딥러닝은 이세돌과 겨룬 컴퓨터 바둑 프로그램 '알파고'에 쓰인 범용 인공지능(AI) 알고리즘이다.
사람이 입력해 준 것만 기억하는 것이 아니라 인간의 두뇌 신경망처럼 스스로 학습해 지식을 확장하고 문제를 해결하는 인공 신경망 기술이 적용된 것이다.
28일 과학잡지 사이언스 등에 따르면, 구글은 27일(현지시간) '구글 신경 기계 번역'(GNMT) 시스템을 이용한 번역 서비스를 시작한다고 발표했다.[https://research.googleblog.com/2016/09/a-neural-network-for-machine.html]
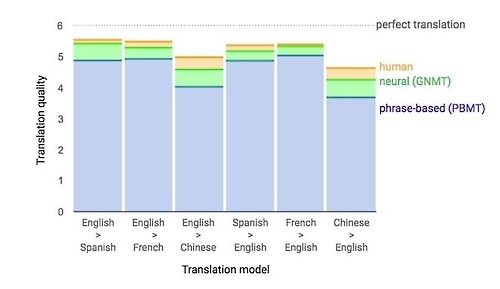 |
| 완벽한 번역을 6점으로 잡았을 때 인간(노란색)과 구글의 기존 PBMT 번역(파란색), 신경망 인공지능번역(녹색)의 현재까지 보인 언어별 번역 실력. [구글 연구 블로그 홈페이지 보도자료 화면 캡처] |
이날은 구글이 인터넷으로 기계 번역 서비스를 시작한 지 10주년 되는 날이다. 기존 서비스는 '문구기반 기계 번역'(PBMT) 시스템을 이용한 것이다.
구글은 GNMT 번역 내용을 사람이 직접 감수한 결과 기존 PBMT 번역에 비해 오류가 평균 60%, 언어에 따라 58%(영어-중국어)에서 87%(영어-스페인어)까지 줄었다고 밝혔다. 이는 위키피디아나 뉴스 사이트에서 추출한 샘플 문장들을 번역한 결과다.
 |
| 중국어 원문 문장, 기존 구글의 PBMT 번역, 새로운 GNMT 번역, 전문가의 번역. 다른 인간 전문가가 번역 내용을 감수했다. [구글 연구블로그 홈페이지 보도자료 화면 캡처] |
기존 PBMT 번역의 경우 입력되는 문장을 단어와 구절로 분해해 각기 이에 대응하는 외국어 단어와 구절로 옮긴 뒤 합성해 문장으로 출력하는 방식이다.
그러나 이번에 내놓은 GNMT 번역은 입력되는 문장을 통째로 읽어 번역한다.
기계가 방대한 단어와 구절, 문장을 기억하고 연관성이 없는 것은 하나씩 없애는 방식으로 정확한 해석을 해나갈 수 있는 학습능력과 방대한 데이터를 빠르게 처리할 수 있는 구조 덕분에 가능하다.
입력된 특정 단어에 대해 인공지능은 훈련에 사용된 방대한 '사전'(영어-프랑스어는 약 25억개 문장 쌍, 중국어는 5억개 문장 쌍)을 뒤져 적합한 단어를 찾아낸다.
개발팀은 GNMT 번역 기술에 대해 설명한 논문에서[http://arxiv.org/pdf/1609.08144v1.pdf] 입력-출력 전 과정이 하나의 신경망에서 이뤄진다고 설명했다.
구글은 이날 웹과 모바일 '구글 번역' 서비스에서 영어-중국어 번역부터 제공하기 시작했으며, 조만간 다른 언어 서비스도 제공할 것이라고 밝혔다.
중국어 서비스부터 시작한 것에 대해 구글 측은 인도-유럽어 간 번역에 비해 중국어의 번역이 가장 어려운 일이어서 이를 정복하는 과정에서 터득한 노하우의 활용도가 클 것이기 때문이라고 설명했다.
또 중국어 사용자가 많고 현재 구글 번역 서비스에서 영어-중국어 번역이 매일 1천800만회나 이뤄지는 점도 고려했다.
사이언스에 따르면, 이번 서비스 개발자들 가운데 중국인(계)가 유독 많은 점도 작용한 것으로 풀이했다.
구글은 이번 번역도 아직 인간의 번역에는 미치지 못하며 적지 않은 오류가 있다고 시인했다. 다만 딥러닝 기반 인공지능의 학습 경험 축적과 관련 기술 등의 발전에 따라 완벽에 가깝도록 진화해나갈 것이라고 강조했다.
<연합>
[ⓒ 세계일보 & Segye.com, 무단전재 및 재배포 금지]
![[설왕설래] 법정싸움으로 치달은 하이브 내분](http://img.segye.com/content/image/2024/04/26/128/20240426514687.jpg
)
![[기자가만난세상] ‘잘 지는’ 리더십](http://img.segye.com/content/image/2023/09/01/128/20230901514421.jpg
)
![[신병주의역사저널] 정조의 안식처, 화성행궁](http://img.segye.com/content/image/2023/03/03/128/20230303514022.jpg
)
![K컬처 부흥 위해서라도, 나는 희망한다 [이지영의K컬처여행]](http://img.segye.com/content/image/2024/03/29/128/20240329514975.jpg
)








